What Is AI Interaction History: a Privacy Guide

Most people think of AI interaction history as a simple chat log. It isn’t. What is AI interaction history, really? It’s a layered record of your inputs, the system’s responses, behavioral signals, metadata, and in some cases, a persistent profile that follows you across sessions. That distinction matters enormously, and not just for tech professionals. Understanding AI interaction history affects how you make privacy decisions, how you use AI for work, and increasingly, how you could be affected in legal contexts. This guide cuts through the confusion and gives you the full picture.
Table of Contents
- Key takeaways
- What is AI interaction history
- How AI uses your history to improve itself
- Privacy, legal, and ethical stakes
- The forgotten conversation problem
- Practical ways to take control
- My take on where this is all heading
- Take control of your AI interaction history
- FAQ
Key takeaways
| Point | Details |
|---|---|
| More than chat logs | AI interaction history includes metadata, behavioral signals, and persistent profiles beyond visible messages. |
| Powers model improvement | Every prompt and correction you send feeds an aggregated dataset that shapes future AI behavior. |
| Real legal exposure | AI conversations lack traditional legal protections and can be subpoenaed as evidence in court. |
| Retrieval is still broken | Most platforms offer poor indexing and search, making past interactions hard to find and use. |
| Local AI changes the equation | Running AI locally keeps your interaction history on your own hardware, not on a vendor’s servers. |
What is AI interaction history
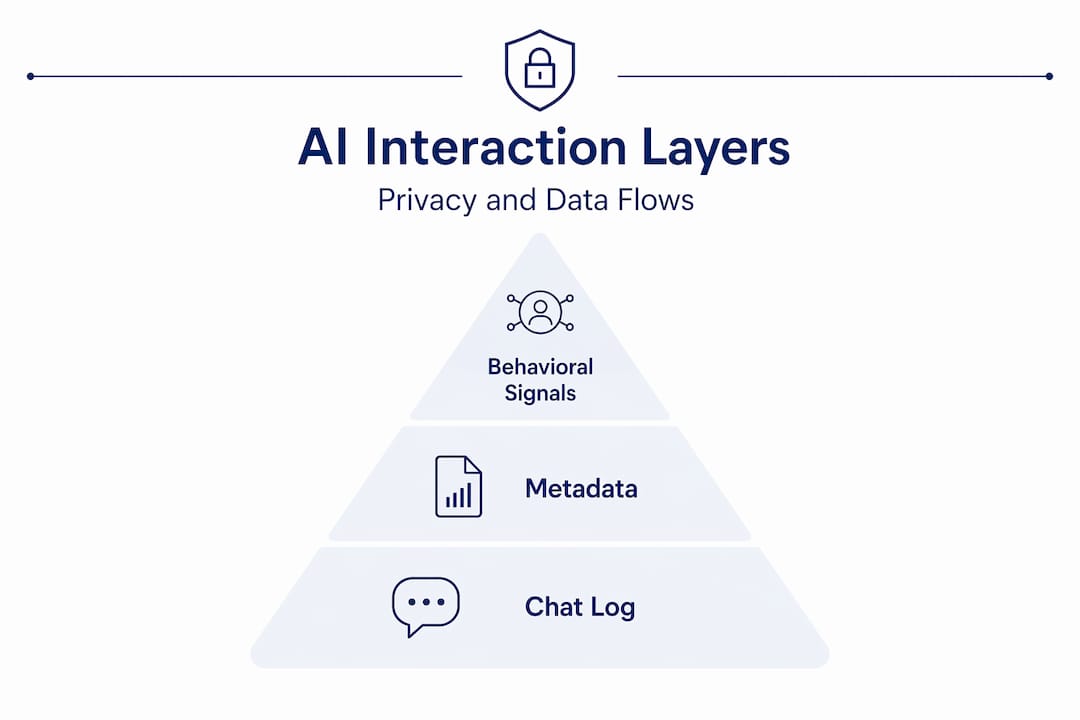
AI interaction history is the full record of everything that passes between you and an AI system during and across sessions. That includes your typed or spoken inputs, the system’s intermediate reasoning steps, final responses, and the metadata attached to each exchange (timestamps, session identifiers, device signals, and more).
There are three distinct layers most people conflate:
- Conversation history: The visible transcript within a single session. When a session ends, many platforms discard this or compress it.
- Session data: Temporary context the model uses during an active conversation to maintain coherence. This is volatile by design.
- Persistent profile: An abstracted layer injected into new sessions as configuration data, simulating memory across conversations without literally storing the full transcript.
That third layer is the one most users never see and rarely think about. It’s also the most consequential for privacy.
On the data side, what gets collected is more extensive than most users realize. Major AI platforms collect up to 35 unique data types per interaction, including financial information and health data. This goes far beyond the words you type. Behavioral signals like how long you spend editing a prompt, whether you regenerate a response, and which parts of an answer you copy are all potentially part of your AI interaction data.
Pro Tip: Treat every AI conversation as if it could be read by a third party. That mindset alone will help you make smarter decisions about what you share.
How AI uses your history to improve itself
Here’s the feedback loop that most users never see. Every interaction you have with a cloud-based AI platform doesn’t just serve you. It feeds a larger system.
Users unknowingly act as unpaid contributors, providing behavioral data that drives model refinement continuously. The mechanism works like this:
- You send a prompt and receive a response.
- Your follow-up action (accepting, editing, regenerating, or abandoning) signals quality feedback to the system.
- Those signals, aggregated across millions of users, identify patterns in model weaknesses and user preferences.
- The model is updated or fine-tuned based on those patterns.
- The cycle repeats with every conversation.
This is what researchers mean when they describe user interactions as a “quiet engine” for AI development. You’re not just a user. You’re a data point in an ongoing training process.
“Every prompt, correction, and follow-up contributes to an aggregated behavioral dataset that shapes the next version of the model you’re talking to.”
The importance of AI interaction extends well beyond personalization. Understanding user behavior patterns at scale reveals which task categories the model handles well and which ones consistently frustrate users. For example, 76% of personal guidance conversations with AI cluster around health, career, relationships, and personal finance. That concentration tells AI developers exactly where to focus refinement efforts.
Pro Tip: If you want cleaner, more predictable AI outputs, make your prompts specific and structured. Vague inputs generate vague training signals, which eventually loop back as vague responses.

Privacy, legal, and ethical stakes
This is where understanding AI interaction history moves from interesting to urgent.
The legal exposure problem
AI chat logs have entered courtrooms. Cases in 2025 and 2026 show AI conversation data being admitted as digital evidence in both criminal and civil proceedings. Unlike communications with a lawyer or therapist, AI chat logs lack legal confidentiality privileges. They can be subpoenaed. They can appear in discovery. And because users often treat AI like a private journal, the disclosures can be significant.
Data retention and regulatory gaps
The table below summarizes key privacy dimensions and their current status across most major cloud AI platforms:
| Privacy dimension | Current reality |
|---|---|
| Data retention period | Varies by platform; often 30 days to indefinite |
| User data deletion rights | Available but sometimes incomplete |
| Third-party data sharing | Common for model improvement and advertising |
| Legal privilege protection | None for AI conversations |
| Regulatory oversight | Fragmented; no unified global standard |
| Transparency of collection | Disclosed in ToS, rarely communicated clearly |
What users should do now
The regulatory framework around AI interaction data is still catching up. In the meantime, your best defenses are behavioral:
- Review the data retention and deletion policies of every AI platform you use regularly.
- Avoid sharing personally identifiable information, medical details, or financial specifics in cloud-based AI conversations.
- For sensitive work, consider platforms that process data locally rather than sending it to remote servers.
- Export or document important conversations yourself. Don’t rely on the platform to store them reliably.
- Understand that “private mode” or “incognito” features on AI platforms vary widely in what they actually protect.
The forgotten conversation problem
Ask anyone who uses AI heavily for work: finding a specific past conversation is genuinely painful. This isn’t a minor UX complaint. It reflects a structural problem with how AI interaction history is stored and accessed.
The core AI chat interface is inherited from messaging apps, which were built for real-time communication, not knowledge management. The result is that your AI interaction history becomes a graveyard of useful thinking that you can’t efficiently retrieve or build on.
The technical side compounds this. AI session files are often stored in raw, non-semantic formats, sometimes hashed, and not structured for human-readable search. You can scroll through conversations, but you can’t search by topic, filter by date range effectively, or link related sessions together.
Some platforms have introduced retrieval-augmented generation (RAG) features and conversational search to partially address this. They help, but they don’t solve the deeper problem. What’s really needed, according to architectural proposals for better AI interaction management, includes:
- Per-message addressability so you can reference a specific exchange later.
- Comprehensive keyword search across all past sessions.
- User-controlled persistence that lets you decide what gets saved and what doesn’t.
- Cross-session linking that treats conversations as connected knowledge artifacts, not isolated transcripts.
Until platforms build these features natively, the burden falls on you to manage your own AI interaction history manually.
Practical ways to take control
Understanding AI interaction history isn’t just an academic exercise. It changes how you work with AI in practice.
For privacy-conscious users, the most significant shift is choosing where your data lives. Cloud-based AI processes your interactions on remote servers. Local AI runs everything on your own hardware. That single architectural difference determines whether your interaction history is yours alone or part of a vendor’s data asset.
For automation and productivity, your AI interaction history is actually underutilized. Most users treat each conversation as disposable. Professionals who get the most value from AI treat interactions as structured, editable workspaces with annotated outputs they can return to. That approach prevents context drift, where the AI loses the thread of a complex project across sessions.
Here are four practical steps worth taking now:
- Audit your platforms. List every AI tool you use and look up their data retention policies. You may be surprised how long your conversations are stored.
- Separate sensitive work. Use local or privacy-first AI tools for anything involving confidential business data, health information, or legal matters.
- Export regularly. Many platforms let you download your conversation history. Do it periodically so you control your own archive.
- Treat AI like a colleague, not a diary. The ELIZA effect causes users to overshare with AI systems because the interaction feels personal. It isn’t. Keep that boundary clear.
Pro Tip: Build a personal knowledge base from your best AI conversations. Copy key insights, decisions, and frameworks into a note-taking tool you control. Your AI history should inform your thinking, not replace it.
My take on where this is all heading
I’ve spent a lot of time thinking about why the conversation around AI interaction history stays surface-level. Most coverage focuses on whether AI is accurate, not on what happens to the record of your conversation afterward. That gap is getting dangerous.
What I find genuinely underappreciated is the paradox at the center of this. Users benefit from AI because it’s trained on vast behavioral data. But that same training pipeline means every conversation you have is, in some sense, a contribution to a system you don’t own and can’t fully audit. You’re simultaneously the customer and the product, and most platforms don’t make that trade-off visible.
The legal dimension is the piece I expect to change everything in the next few years. Once more people realize their AI conversations can appear in discovery proceedings without any privilege protection, the demand for private, local AI will accelerate sharply. This isn’t speculation. It follows the same trajectory as encrypted messaging adoption after the Snowden disclosures.
What I believe we need urgently is a generation of AI interfaces that treat interaction history as a first-class user asset. Not a vendor asset. Not training data. Yours. That means local storage by default, user-controlled deletion, and genuinely searchable archives. A few platforms are moving in this direction. Most aren’t. The users who understand what’s at stake will make better choices about which tools they trust with their thinking.
— steve
Take control of your AI interaction history
If this article has made one thing clear, it’s that your AI interaction history is valuable, and not just to you. The platforms you use today are collecting, analyzing, and in many cases retaining that data in ways most users never examine.

Mingllm is built on a different premise entirely. It runs on your macOS device locally, which means your conversations, your memory layers, and your reasoning processes never leave your hardware. There’s no vendor server storing your session data, no behavioral signals being harvested for model training, and no risk of your AI history showing up in a legal discovery process. For professionals and privacy-conscious individuals who want the full power of personal AI without the trade-offs, Mingllm’s local AI platform is worth a close look.
FAQ
What does AI interaction history actually include?
AI interaction history includes your text or voice inputs, the system’s responses, session metadata, behavioral signals like edits and regenerations, and in many cases a persistent profile layer that carries context across multiple conversations.
Can my AI conversations be used in court?
Yes. AI chat logs have been admitted as evidence in criminal and civil cases, and unlike lawyer or therapist communications, they carry no legal confidentiality protection. They can be subpoenaed without restriction.
How do AI platforms track interactions?
AI interaction tracking methods include logging message content, timestamps, session identifiers, device data, and behavioral signals such as response edits and regenerations. Some platforms also build persistent user profiles that persist across sessions.
Why is past AI conversation history so hard to find?
Most platforms store AI session files in raw, non-semantic formats without robust indexing or keyword search. The chat interface was inherited from messaging apps, not built for knowledge retrieval.
What is the safest way to protect my AI interaction data?
Use a local AI platform that processes everything on your own hardware, avoid sharing sensitive personal or financial details in cloud-based AI tools, and regularly export your conversation history so you control your own archive.