Private AI vs Surveillance AI: What You Must Know

Most people assume that “private AI” automatically means freedom from surveillance. That assumption is dangerously incomplete. The debate around private ai vs surveillance ai runs far deeper than encryption checkboxes or marketing promises. Where your data is processed, who can access metadata logs, and whether national security exemptions apply to your AI provider all determine your actual privacy posture. If you care about personal data security and user autonomy, you need to understand both the architecture and the politics at play before trusting any AI system with your life.
Table of Contents
- Key takeaways
- How private AI actually works
- How surveillance AI captures and uses your data
- Comparing privacy and autonomy across both models
- Reducing privacy risks in surveillance AI
- My take on what privacy advocates are missing
- Why Mingllm is built for this moment
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Private AI is not a guaranteed shield | Privacy depends on full lifecycle governance, not just encryption at rest or in use. |
| Surveillance AI scales through interoperability | Connected sensor networks compound privacy risks far beyond what isolated devices produce. |
| GDPR Article 22 protects automated decisions | You have legal rights to contest significant automated decisions, but enforcement varies widely. |
| Edge AI reduces surveillance exposure | Processing data on-device shrinks the attack surface by limiting raw data transmission to the cloud. |
| Architecture reveals true privacy | Ask where data leaves secure enclaves, what metadata is logged, and who can access training data. |
How private AI actually works
The phrase “private AI” covers a spectrum of architectural choices, not a single standard. At the technical core, the strongest privacy-focused AI systems use confidential computing, specifically secure enclaves that isolate computation so that even the infrastructure provider cannot read plaintext data or inference results. Private AI systems like those using enclave-based architectures apply runtime encryption, meaning data stays protected not just when stored but while actively being processed.
Several mechanisms define genuinely privacy-preserving AI:
- On-device processing: Models run locally on user hardware, so raw inputs never leave the device.
- Data minimization: Systems collect only what is necessary for the task, reducing exposure by design.
- Anonymization with defensibility: GDPR-compliant anonymization requires demonstrable proof that models cannot leak personal data through extraction attacks or targeted queries.
- Remote attestation: Cryptographic verification confirms that code executing inside an enclave has not been tampered with, protecting both user and provider integrity.
- No training on user data: The clearest privacy line is whether your conversations or inputs are ever used to fine-tune or update models.
The regulatory backdrop matters too. Privacy by design under GDPR is not optional for AI systems operating in the EU. The NIST AI Risk Management Framework codifies data privacy as a core risk category alongside cybersecurity, treating it as a lifecycle responsibility rather than a one-time feature.
Pro Tip: When evaluating any private AI claim, ask specifically about metadata logging outside enclaves. A system might protect your query content while still logging timestamps, session lengths, and IP addresses in ways that remain identifiable.
The honest limitation of private AI is that no architecture eliminates all risk. Model leakage through carefully crafted queries, residual data in inference caches, and unclear incident response policies all represent gaps that encryption alone does not close. Real-world privacy hinges on enclave boundaries, what metadata leaves those boundaries, and whether user data ever touches training pipelines.
How surveillance AI captures and uses your data
Surveillance AI is not a monolithic technology. It is a stack. A typical deployment connects edge sensors such as cameras, license plate readers, and drones to cloud-based analytics platforms that aggregate, correlate, and retain data across jurisdictions. U.S. cities operate facial recognition cameras, automated license plate readers, and drone feeds connected to shared analytics systems that enable cross-agency data sharing with minimal oversight.
The privacy risks compound at every layer of that stack:
- Scale: A single camera captures thousands of individuals who have not consented to identification.
- Retention: Data persists in cloud systems long after the incident that justified collection has resolved.
- Interoperability: When surveillance systems share data, the network effect increases inference power and enables secondary uses that were never part of the original purpose.
- Automated decisions: Systems flag, score, and sometimes deny access to individuals based on AI outputs, often without human review.
“Surveillance AI’s autonomy impact shifts from accuracy concerns to the difficulty individuals have in understanding or limiting their data inclusion.” This isn’t a technical problem with a technical fix. It’s a governance failure.
Legal protections exist but are uneven. GDPR Article 22 grants individuals the right to contest solely automated decisions that produce significant legal or personal effects, and it requires human intervention safeguards. The problem is that many surveillance deployments operate in public spaces where consent is impossible to obtain and contestability is practically inaccessible. Security benefits are real. Facial recognition does help identify genuine threats. But the question privacy advocates must ask is whether those benefits justify the breadth of data capture imposed on everyone else.
Comparing privacy and autonomy across both models
Understanding private ai vs surveillance ai requires looking at specific dimensions side by side, not just slogans.
| Dimension | Private AI | Surveillance AI |
|---|---|---|
| Data processing location | On-device or within secure enclaves | Edge sensors feeding centralized cloud |
| User consent | Explicit, user-initiated | Often absent or impractical to withhold |
| Data retention | Minimal, often session-only | Extended, sometimes indefinite |
| Access control | User holds keys or controls scope | Provider, government, or third parties |
| Automated decision rights | User can audit or halt processes | Limited recourse under most frameworks |
| Metadata exposure | Varies by architecture and policy | High, due to interoperability requirements |
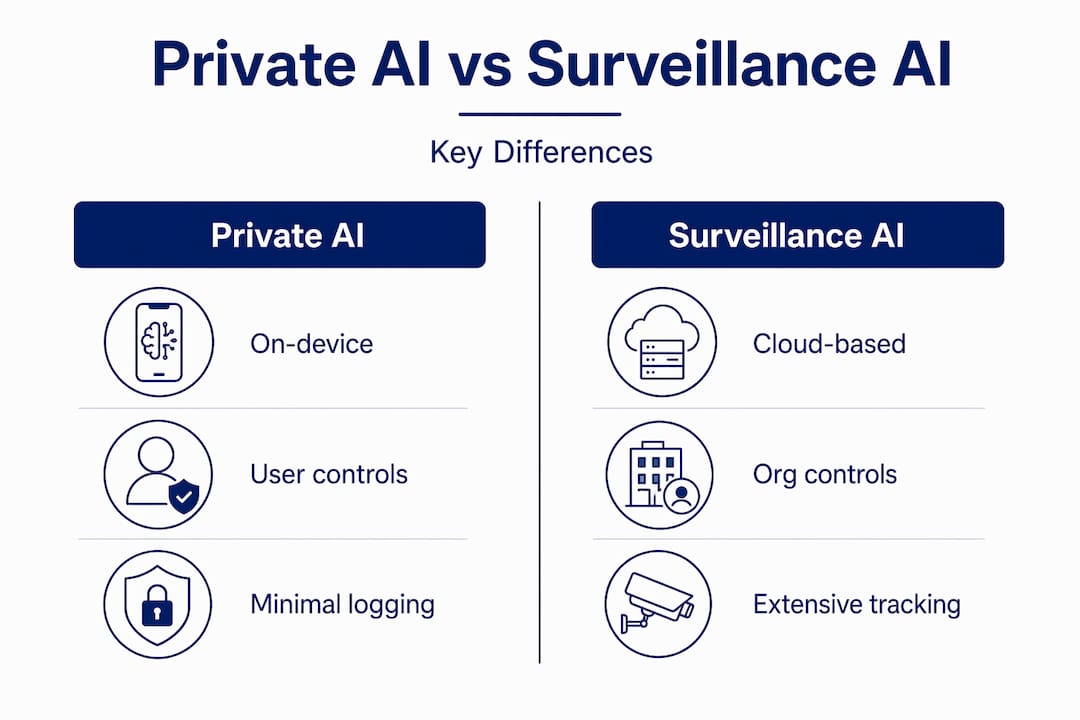
The comparison reveals something uncomfortable: private AI and surveillance AI are not simply opposites. A privacy-focused AI system could still log metadata that enables profiling. A surveillance system could incorporate edge processing that reduces data egress. The real question is always who controls the data, for how long, and under what legal authority.
Governance shapes outcomes more than technology does. NIST’s AI RMF defines trustworthy AI as encompassing privacy enhancement, safety, fairness, and explainability across the full AI lifecycle. A private AI system that checks the encryption box but lacks explainable data policies is not actually trustworthy by that standard.
Pro Tip: Do not trust AI privacy claims that rely entirely on technical safeguards. Ask for written policies on data retention, incident response, and whether national security requests can override privacy protections.
Marketing language is the biggest practical risk. Providers use terms like “privacy-first” and “zero-knowledge” with no standardized definitions. Until regulatory frameworks enforce these claims with auditable standards, you need to read architecture documentation, not marketing copy.
Reducing privacy risks in surveillance AI
Even within surveillance contexts, architectural choices dramatically change the privacy calculus. The goal is not to eliminate surveillance AI where legitimate security needs exist, but to design it in ways that limit unnecessary exposure.
- Move inference to the edge. Edge AI inference runs in 20 to 100 milliseconds versus 300 to 800 milliseconds for cloud-based processing, and it keeps raw video on-device rather than streaming it to centralized servers. Privacy and performance improve together.
- Apply data minimization at capture. Cameras should transmit alerts or metadata rather than full video streams wherever the use case permits. Retaining a license plate match is less invasive than retaining the associated vehicle footage.
- Enforce purpose limitation. Data collected for one use case, say, identifying stolen vehicles, should be technically and legally blocked from secondary uses like immigration enforcement or protest monitoring.
- Anonymize before aggregation. Where individual identification is not required, faces and biometrics should be blurred or hashed before data enters shared analytics platforms.
- Audit interoperability agreements. Every data-sharing contract between surveillance AI vendors and government agencies should specify retention limits, allowable secondary uses, and deletion obligations. Most currently do not.
The architecture of surveillance AI is not fixed. Cities and organizations that take AI privacy concerns seriously can build systems that serve security needs without enabling mass profiling. The barrier is usually political will, not technical capability.
My take on what privacy advocates are missing
I’ve spent years watching the private AI narrative develop, and what frustrates me most is the binary framing. People treat private AI as automatically good and surveillance AI as automatically bad, and both assumptions lead to bad decisions.
In my experience, the bigger threat to privacy-conscious users is not the surveillance camera on the street corner. It’s the “private” AI product that runs in a cloud enclave but retains metadata about every session, shares incident data with model developers, and has a terms of service that includes national security carve-outs. Policy conflicts make clear that embedded AI safeguards can be overridden by governmental intelligence priorities. That clause exists in more privacy-first products than users realize.
What I’ve learned is that you should demand three specific things from any AI system claiming to protect your privacy: a published architecture diagram showing where data leaves secure boundaries, a clear incident response policy stating what happens if they receive a government data request, and third-party audit results, not just self-certification. The products that refuse to provide all three are telling you something important.
Surveillance AI deserves scrutiny, but it also deserves nuanced governance rather than blanket bans. The goal is accountability at every layer of the stack: sensors, transmission, analytics, retention, and secondary use. Technology can help, but only policy with teeth makes it stick.
— steve
Why Mingllm is built for this moment
If the architecture question matters to you, the only real answer is running AI locally. Mingllm is built on exactly that principle: models, memory, and reasoning all execute on your device, with no cloud dependency and no data leaving your hardware.

For macOS users who want voice agents, browser research tools, and deep workflow integration without feeding a surveillance stack, Mingllm delivers genuine local-by-default AI. There is no remote attestation theater here. Your data stays where you put it. If the discussion in this article made you want to verify rather than trust, that is precisely the mindset Mingllm was designed for. Check out the personal AI platform and see what local-first AI actually looks like in practice.
FAQ
What is the core difference between private AI and surveillance AI?
Private AI processes data on-device or within isolated secure enclaves, keeping user data under personal control. Surveillance AI captures data from public or semi-public spaces and routes it through centralized analytics systems, often without individual consent.
Does private AI guarantee protection from surveillance?
No. Private AI is not a guaranteed blocker of surveillance risks because privacy depends on complete lifecycle governance, including metadata policies, training data use, and legal carve-outs, not encryption alone.
What rights do I have under GDPR when surveillance AI makes decisions about me?
GDPR Article 22 grants you the right to contest automated decisions that produce significant legal or personal effects, and requires that human intervention be available. Enforcement varies significantly by jurisdiction.
How does edge AI processing reduce surveillance privacy risks?
Edge AI inference keeps raw data on-device rather than streaming it to cloud servers, reducing exposure to interception, unauthorized retention, and secondary use by third parties.

What should I look for when evaluating an AI product’s privacy claims?
Ask for a published architecture document showing enclave boundaries and metadata logging practices, a written policy on government data requests, and third-party audit results. Products that cannot provide all three offer weaker privacy protections than their marketing suggests.